Trasferimento Blog
Da oggi, martedì 10 Aprile 2007, il blog sarà disponibile all’indirizzo http://blog.marcoccia.net.
Pasquale
Vector VS ArrayList
E’ da un pò che non scrivo sul blog (troppo lavoro…), lo faccio oggi per una questione che si è aperta qualche giorno fa nel team di sviluppo con cui collaboro da qualche mese. Vado al sodo (tanto siete già passati per il titolo, no?): meglio Vector o ArrayList?
Innanzitutto non c’è alcun motivo per cui a priori si debba optare per l’una o per l’altra indistintamente. In quest’articolo la scelta dell’implementazione da utilizzare verte sui seguenti fattori:
-
le API
Dal punto di vista delle API, le due classi sono praticamente analoghe. Ci sono solo alcune quisquilie che intrecciate agli altri fattori possono fare la differenza. -
la concorrenza
Per quanto concerne la concorrenza, i Vector sono thread safe, mentre dall’altra parte gli ArrayList non lo sono. Il prezzo della sincronizzazione lo si paga in termini di performance (quanto sia questo prezzo lo vedremo in seguito).
Qui si potrebbe già effettuare una prima scelta: se non si hanno problemi sulla concorrenza… Why pay the price of synchronization unnecessarily? -
la dinamica di crescita degli elementi
Internamente, nella loro implementazione, ArrayList e Vector gestiscono gli elementi con un Array. Se quando si instanzia la lista non si indica la grandezza, ArrayList e Vector cambiano dinamicamente la grandezza del loro Array interno e giustamente lo fanno solo quando non c’è più spazio per il nuovo elemento che si desidera inserire. La differenza sostanziale tra ArrayList e Vector, in questo caso, sta nella nuova grandezza che l’array interno assume: ArrayList lo aumenta del 50%, Vector lo raddoppia.
Ecco perchè il guru di Java sconsiglia di instanziare una lista e incominciare ad addare gli elementi in maniera brutale. E’ preferibile infatti settare una grandezza massima alla lista, tale da rientrare con gli inserimenti ed evitare di pagare il resize dinamico dell’array interno.
Vector ha però un vantaggio: se si conosce il rate con cui crescono gli inserimenti è possibile settare il valore di incremento dell’array interno (con le API a tempo di costruttore). -
le operazioni
Sia ArrayList che Vector permettono di recuperare un elemento in una determinata posizione e di aggiungere o rimuovere in coda al costo di O(1). Aggiungere o rimuovere elementi in una qualsiasi altra posizione ha costo lineare O(n), in quanto è necessario lo shift (rispettivamente in avanti o in indietro) degli elementi successivi. In particolare, se risulta quest’ultima l’operazione dominante, allora sarebbe utile scartare sia ArrayList che Vector ed utilizzare LinkedList, che aggiunge o rimuove elementi al costo di O(1), in cambio di un peggiore costo per l’indicizzazione e di un maggiore garbage (viene costruito un oggetto interno per ogni elemento).
Ho lasciato in sospeso il discorso sul costo effettivo della sincronizzazione di Vector. Lo affronto con la prova sul campo e più precisamente con una classe di test (la trovate qui) e, armato del più semplice microbenchmark, System.currentTimeMillis(), misurerò le differenze di performance tra le due implementazioni.
Se siete arrivati fin qui e ancora siete indecisi se per il vostro caso è meglio ArrayList o Vector, potreste far girare questo test sull’ambiente di esecuzione eclissando ogni responsabilità con i benefici della scelta effettuata.
Naturalmente nell’era del multiprocessore e con una JVM multithreading non mi sento di stabilire sentenze dopo un semplice run, consiglio quindi di lanciare più run e di stabilire una media dei tempi su cui poter trarre delle conclusioni affidabili.
La classe di test (il cui nome non può dare scapito a fraintendimenti) va lanciata con i seguenti parametri:
-
[warmup] – Rappresenta il numero di iterazioni che si vogliono effettuare sulla lista; queste iterazioni non vengono misurate ma hanno lo scopo di far sì che la JVM possa effettuare le sue ottimizzazioni.
-
[num] – Rappresenta il numero di elementi da inserire nella lista.
-
[outer] – Rappresenta il numero di volte che si vuole iterare per intero la lista.
-
[sleep] (in msec) – Rappresenta l’attesa tra il warmup e il test taimizzato. Ha lo scopo di rilasciare il processore per un lasso di tempo e permettere alla JVM di completare il processo di compilazione in background.
-
[total] – Rappresenta il numero di run (il numero di tests da effettuare).
I risultati effettuati su una macchina con processore Intel P4, 1GB Ram con WindowsXP Professional e JVM 1.5 update 9 sono i seguenti:
-------------------------------------------------------------- VectorVSArrayList 3000 3000 3000 500 50 -------------------------------------------------------------- Testing with warmup: 3000 num: 3000 outer: 3000 sleep: 500 total: 50 Vector 1156msec ArrayList 250msec Vector 1141msec ArrayList 250msec Vector 844msec ArrayList 235msec Vector 766msec ArrayList 235msec Vector 1172msec ArrayList 234msec Vector 813msec ArrayList 234msec [...]
I dati indicano approssimativamente una velocità di ArrayList superiore di circa 3-4 volte rispetto a Vector.
I risultati effettuati su una macchina con processore Intel P4, 1GB Ram con Ubuntu 6.06 e JVM 1.5 update 9 sono i seguenti:
-------------------------------------------------------------- VectorVSArrayList 3000 3000 3000 500 50 -------------------------------------------------------------- Testing with warmup: 3000 num: 3000 outer: 3000 sleep: 500 total: 50 Vector 650msec ArrayList 233msec Vector 631msec ArrayList 215msec Vector 544msec ArrayList 204msec Vector 566msec ArrayList 215msec Vector 572msec ArrayList 214msec Vector 513msec ArrayList 214msec [...]
Anche in questo caso i dati indicano una velocità di ArrayList superiore, ma dell’ordine di 2 volte e mezzo circa.
I risultati effettuati sulla macchina precedente ma utilizzando JVM 1.6 sono i seguenti:
-------------------------------------------------------------- VectorVSArrayList 3000 3000 3000 500 50 -------------------------------------------------------------- Testing with warmup: 3000 num: 3000 outer: 3000 sleep: 500 total: 50 Vector 570msec ArrayList 180msec Vector 531msec ArrayList 149msec Vector 504msec ArrayList 158msec Vector 506msec ArrayList 150msec Vector 512msec ArrayList 149msec Vector 501msec ArrayList 148msec [...]
La JVM 1.6 ha aumentato le performance di entrambe le implementazioni, ma per ArrayList la differenza è tale che adesso è più veloce di oltre 3 volte rispetto a Vector (avvicinandosi ai dati del primo test).
In tutti i test portando il warmup al valore di 1, la prima iterazione è di quasi 2 volte più lenta rispetto ai tempi delle successive.
Mentre se si riduce ad 1 solo msec lo sleep i tempi in totale sono più lenti di una volta e mezza ed il tempo ottimizzato viene raggiunto dopo circa 3 o anche 4 iterazioni.
Come concludere? Beh, io credo che, se per decidere, si è ridotti a dover far girare questi test allora si rischia poi di non dormirci la notte.
Alla prossima…
Uno slider multi thumb per Java Swing
Anno nuovo, vita nuova… Ho abbandonato JBoss e sono passato su qualcosa che ho sempre sfiorato ma che, vuoi per un motivo vuoi per un altro, ho poi sempre schivato con destrezza. Questa volta però un pò me la sono cercata (in fondo gli ostacoli vanno affrontati, no?) e quindi eccomi qui a combattere con Java Swing!
Non voglio certo annoiarvi sugli aspetti positivi (e ahimè negativi) che un programmatore incontra nel costruire una piacevole (ma soprattutto intuitiva) GUI in Java. Mi soffermerò, invece, su un particolare componente e su un suo possibile utilizzo.
Lo slider è un componente che permette facilmente di selezionare un valore compreso in un certo range. E’ implementato dalla classe JSlider e, come potete notare nella figura sotto, rispecchia le nostre richieste: è piacevole e intuitivo.

Il problema è che, per l’applicazione che sto sviluppando, avrei bisogno di uno slider con più cursori (thumb), per la precisione uno slider con tre cursori. Come è mio solito fare, ho interrogato l’oracolo Google, ma non ho trovato qualcosa di utilizzabile, e quindi olio di gomito…
I requisiti: ho bisogno di 3 cursori, su ogni cursore deve essere mostrato il suo valore e, infine, mi piacerebbe che il componente s’integrasse con il Look&Feel scelto… chiedo troppo?
Ah! Dimenticavo: non amo farmi del male… ma mentre sviluppavo ho aggiunto la parametrizzazione del numero dei cursori come ulteriore requisito… non si sa mai, questo componente potrebbe tornarmi utile un domani.
La classe completa che implementa lo SliderMultiThumb (il nome scelto mi sembra più che appropriato no?) la trovate qui. Vediamo, a grandi linee, come ci sono arrivato. L’idea è quella di gestire l’intera barra come valore unitario (di conseguenza valore minimo 0 e valore massimo 1) e di avere tutti i valori dei cursori in centesimi.
private static final double DEFAULT_VALUE_MAX = 1; private static final double DEFAULT_VALUE_MIN = 0; // number of thumbs private int thumbs; // thumb values (centesimal) private double thumbValuesCentesimal[]; // thumb max & min values private double maxValue = DEFAULT_VALUE_MAX; private double minValue = DEFAULT_VALUE_MIN;
Il costruttore dello SliderMultiThumb richiede come argomento l’intero, che definisce il numero di cursori richiesti.
/**
* Constructs and initializes the slider.
*
* @param thumbs thumbs' number
*/
public SliderMultiThumb(int thumbs){
[...]
}
Una volta costruito il componente, se non passo i valori dei cursori, utilizzando il metodo setValueThumbs(double[] valueThumbs), gli stessi dovranno posizionarsi in modo equidistante tra di loro. Pertanto nel costruttore:
// setting value for each thumbs... i want to put each thumb at the same distance with other ones
double[] valueThumbs = new double[thumbs];
final double valueAverage = (maxValue - minValue) / (thumbs + 1); // thumbs + 1 = the spaces between thumbs
for (int i=0; i < thumbs; i++){
valueThumbs[i] = minValue + valueAverage * (i + 1);
}
setValidValueThumbs(valueThumbs, false);
Ad ogni cursore devo associare un valore non solo relativo all’effettiva entità tra il minimo e il massimo, ma anche alla posizione (in senso grafico) sull’asse x (ho previsto per SliderMultiThumb solo l’implementazione orizzontale). Il metodo setValidValueThumbs, quindi, calcola lo spazio che sull’asse delle x rimane dopo aver eliminato quello utilizzato per disegnare i cursori (l’ampiezza del cursore è definita da una costante) e lo distribuisce ai vari cursori, secondo la percentuale del proprio valore.
// total is the available space without the thumbs' paint
double total = (double)( componentWidth - (THUMB_WIDTH * thumbs * 2) );
for (int i=0; i < thumbValuesCentesimal.length; i++){
// get centesimal value
if (!isCentesimal){
thumbValuesCentesimal[i] = (valueThumbs[i] - minValue) / (maxValue - minValue);
}
// ...and then new position is the percentual value of total and previous thumbs' with additionally one (for this)
pixPosition[i] = (int)((thumbValuesCentesimal[i] * total) + THUMB_WIDTH * (2*i + 1) );
}
Il metodo paint disegna l’intero componente, dividendolo in 2 regioni in cui mostrare rispettivamente i valori dei cursori e la barra con i cursori.
int width = getSize().width; int height = getSize().height; // text region g.setColor( getBackgroundColor() ); g.fillRect( 0, 0, width, TEXT_HEIGHT ); // region where thumbs run along g.setColor( getBackgroundColor() ); g.fillRect( 0, TEXT_HEIGHT, width, height - TEXT_HEIGHT); // nice line in the middle of the bar with light shape g.setColor( Color.DARK_GRAY ); g.fillRect( 0, TEXT_HEIGHT + (height - TEXT_HEIGHT) / 2, width, 1); g.setColor( Color.lightGray ); g.fillRect( 0, TEXT_HEIGHT + (height - TEXT_HEIGHT) / 2 - 1, width, 1);
Il disegno dei cursori viene fatto ciclando sull’array pixPosition, che come visto precedentemente, mi dà l’esatta posizione del cursore. Avendo il disegno del cursore con sopra il rispettivo valore (renderizzato in base al vero minimo e massimo settato), può capitare che, avvicinando due cursori al massimo (ovvero facendo in modo che abbiano lo stesso valore), le scritte in alto collidano (ma non perfettamente). Pertanto, in caso di stessi valori tra più cursori, la scritta viene disegnata solo una volta, centrandola rispetto ai cursori.
// now print thumb value... if other thumbs have same value go on... (avoid to print same value up each thumb)
if (i == pixPosition.length - 1 || thumbValuesCentesimal[i] != thumbValuesCentesimal[i+1]){
// check the first thumb with the same value
int firstThumbWithSameValue = i;
for (int j=i; j >= 0; j--){
if (thumbValuesCentesimal[j] != thumbValuesCentesimal[i]){
break;
}
firstThumbWithSameValue = j;
}
final String value = render( getValue(i) ).trim();
final int spaceText = getFontMetrics(getFont()).stringWidth(value); // space used by text (in pixels)
int xTextPosition = pixPosition[firstThumbWithSameValue] + (pixPosition[i] - pixPosition[firstThumbWithSameValue]) / 2 - spaceText / 2;
// this check is to avoid that thumb taken to the max value (or min), have their value written outside the component
if (xTextPosition + spaceText > width){
xTextPosition = width - spaceText;
} else if (xTextPosition < 0){
xTextPosition = 0;
}
g.setFont(getFont());
g.drawString(value, xTextPosition, TEXT_HEIGHT - TEXT_BUFFER);
Adesso occorre far sì che i cursori si muovano… è necessario aggiungere un MouseAdapter per la pressione del mouse e un MouseMotionAdapter per lo spostamento con pressione dello stesso. Entrambi gli eventi passano la posizione del puntatore sull’asse delle x ad handleMouse, che trova il cursore più vicino:
// check thumb closer
int thumbCloser = 0;
int xDistance = Integer.MAX_VALUE;
for (int i=0; i < pixPosition.length; i++){
int dist = Math.abs(pixPosition[i] - x);
if (dist < xDistance){
thumbCloser = i;
xDistance = dist;
}
}
Successivamente devo trovare il limite alla mia sinistra (che potrebbe essere il valore minimo nel caso in cui sto muovendo il primo cursore) e il limite alla mia destra (che potrebbe essere il valore massimo nel caso in cui sto muovendo l’ultimo cursore). Ciò che devo fare è aggiornare la posizione del cursore selezionato (thumbCloser) alla posizione passatami dai listeners, facendo attenzione a non superare i limiti.
// now check where is my limit on the left
int left = 0; // if i'm moving the first thumb then my limit on the left is 0
int xMinLeft = THUMB_WIDTH;
if (thumbCloser != 0){ // otherwise will be the thumb on my left
left = pixPosition[thumbCloser - 1];
xMinLeft = THUMB_WIDTH * 2;
}
// now check where is my limit on the right
int right = componentWidth; // if i'm moving the lst thumb then my limit on the left is component's width
int xMinRight = THUMB_WIDTH;
if (thumbCloser != thumbs - 1){ // otherwise will be the thumb on my right
right = pixPosition[thumbCloser + 1];
xMinRight = THUMB_WIDTH * 2;
}
[...]
// if exceeded limit...
if (x < right - xMinRight){
x = right - xMinRight;
}
Ecco come si presenta lo SliderMultiThumb con 4 cursori:
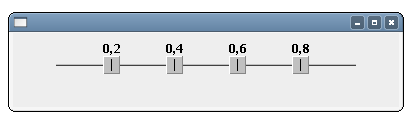
Ho sorvolato su alcune banalità, tipo la possibilità di visualizzare o meno i valori decimali o il colore di background… Per esempio, per avere uno slider di colore arancio, con 4 cursori che spaziano su un range che va da -100 a 400, utilizzando solo valori interi e con una situazione iniziale che prevede il primo cursore a -80, il secondo e terzo appaiati a 0 e l’ultimo sul valore 230, scriveremo:
JPanel p = new JPanel();
SliderMultiThumb smt = new SliderMultiThumb(4);
smt.setRange(-100, 400);
smt.setShowDecimalValues(false);
smt.setBackgroundColor( Color.orange );
smt.setValueThumbs(new double[]{-80, 0, 0, 230});
p.add(smt);
…e questo è l’esito grafico:
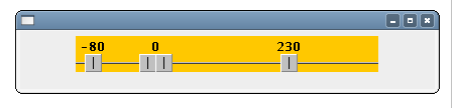
Manca solo la rendizzazione con il Look&Feel selezionato… ma per ora va bene così, se un giorno mi ritroverò a girare i pollici (beata gioventù!) probabilmente scriverò “Uno slider multi thumb per Java Swing 2”. Alla prossima 😉
Servizi JMS transazionali in JBoss AS 4.x
Dopo aver tirato su i servizi JMS su JBoss AS 4.x, con tanto di MDB e MessageProducer, vediamo ora come inserire il tutto in un ambiente transazionale.
Quando arriva un nuovo messaggio sulla coda, l’MDB che è in ascolto riceve una chiamata onMessage() che inizia una nuova transazione JTA. Poniamo il caso che l’MDB debba eseguire una serie di operazioni in seguito all’arrivo del nuovo messaggio; se una di queste operazioni va in errore, l’MDB non deve scodare il messaggio (dare l’aknowledge) ma fare rollback dell’intero processo. Inoltre preferirei che il messaggio venga riproprosto dopo un tempo di attesa definito e per un numero massimo di tentativi.
Prima di tutto impostiamo il livello di transazione per l’MDB a RequiresNew per il metodo onMessage, in modo che all’arrivo di un nuovo messaggio il container inizi una nuova transazione:
ejb-jar.xml
<ejb-jar>
<enterprise-beans>
[...]
</enterprise-beans>
<assembly-descriptor>
<container-transaction>
<method>
<ejb-name>MyMDBBean</ejb-name>
<method-name>onMessage</method-name>
</method>
<trans-attribute>RequiresNew</trans-attribute>
</container-transaction>
</assembly-descriptor>
</ejb-jar>
L’interfaccia MessageDrivenContext deriva dalla EJBContext e ne nasconde quei metodi che nell’ottica dei MessageDrivenBean non hanno alcuna utilità (vd. getEJBHome(), getEJBLocalHome(), getCallerPrincipal() e isCallerInRole()). Il MessageDrivenContext rimane associata all’istanza del bean per tutto il ciclo della sua vita e ne rappresenta il legame con il container.
MyMDBBean.java
[...]
public void setMessageDrivenContext(MessageDrivenContext messageDrivenContext) throws EJBException {
this.messageDrivenContext = messageDrivenContext;
}
public void onMessage(Message message) {
logWriter.debug("---------- Start onMessage() -----------");
logWriter.debug("Ricevuto nuovo messaggio nella coda");
try {
// do something...
} catch (Exception ex) {
logWriter.error("error: ", ex);
messageDrivenContext.setRollbackOnly();
}
logWriter.debug("---------- End onMessage() -----------");
}
Per legare la connessione con i servizi JMS alla transazione JTA occorre utilizzare la ConnectionFactory sotto il JNDI Name java:/JmsXA. Questa connection factory è l’unica a supportare JTA, mentre le altre connection factories (per es. ConnectionFactory) supportano solo le transazioni locali. Per far sì che il nostro MDB sia legato alla coda tramite suddetta ConnectionFactory occorre definirlo con i tag resource-ref in ejb-jar.xml e jboss.xml.
ejb-jar.xml
<ejb-jar>
<enterprise-beans>
<message-driven>
[...]
<resource-ref>
<res-ref-name>jms/ConnectionFactory</res-ref-name>
<res-type>javax.jms.ConnectionFactory</res-type>
<res-auth>Container</res-auth>
</resource-ref>
</message-driven>
</enterprise-beans>
<assembly-descriptor>
[...]
</assembly-descriptor>
</ejb-jar>
jboss.xml
<jboss>
<enterprise-beans>
<message-driven>
[...]
<resource-ref>
<res-ref-name>jms/ConnectionFactory</res-ref-name>
<jndi-name>java:/JmsXA</jndi-name>
</resource-ref>
</message-driven>
</enterprise-beans>
</jboss>
Se siete fortunati ed utilizzate EJB 3.0, la specifica prevede la seguente annotation:
@Resource(mappedName="java:/JmsXA") ConnectionFactory connFactory;
Infine occorre gestire la ritrasmissione dei messaggi in caso di errore. Per far ciò è necessario aggiungere dei parametri alla configurazione della coda.
myapp-destinations-service.xml
<server>
<mbean code="org.jboss.mq.server.jmx.Queue" name="jboss.mq.destination:service=Queue,name=MyQueue">
<depends optional-attribute-name="DestinationManager">jboss.mq:service=DestinationManager</depends>
<depends optional-attribute-name="SecurityManager">jboss.mq:service=SecurityManager</depends>
<attribute name="MessageCounterHistoryDayLimit">-1</attribute>
<attribute name="RedeliveryLimit">3</attribute>
<attribute name="RedeliveryDelay">300000</attribute> <!-- 5 min -->
</mbean>
</server>
Il parametro “RedeliveryLimit” indica i tentativi di re-inoltro del messaggio prima di settarlo completamente in errore e spedirlo nella coda standard DLQ (Dead Letter Queue). Il parametro “RedeliveryDelay” indica il tempo (in msec) da attendere prima di ritentare l’inoltro di un messaggio precedentemente andato in errore.
…e anche questa è andata.
Un MDB singleton in un cluster di JBoss AS 4.x
Finisce anche questa settimana… contraddistinta dal’imperversare dell’influenza in ufficio (…proprio ora sono di ritorno dalla visita medica). Entro questa settimana mi ero prefissato di tirar su un singleton MDB in un ambiente JBoss clusterizzato e, nonostante le notti insonni per il naso completamente chiuso, alla fine ci sono riuscito.
JBoss Messaging è un JMS Provider ad altissime prestazioni, è una completa riscrittura di JBossMQ (il JMS Provider di default in JBoss AS 4.x) e sarà il JMS Provider di default in JBoss AS 5.x. Purtroppo, alla sua attuale versione, 1.0.1.GA, JBoss Messaging non offre supporto al clustering e dovrò pertanto utilizzare JBossMQ, riservandomi la possibilità di switchare a JBoss Messaging quando verrà rilasciata la versione 1.0.2. Il passaggio non dovrebbe riservare grosse criticità in quanto JBoss Messaging implementa JMS 1.1 ed è compatibile con JMS 1.0.2b, pertanto il codice JMS scritto per JBossMQ può girare senza alcuna modifica in JBoss Messaging… ma questa è qualcosa che potrò confermare solo al momento opportuno.
Prima di addentrarmi nella configurazione JMS, ho preferito focalizzare bene le mie conoscenze sulla gestione del cluster da parte di JBoss.
JBoss offre pieno supporto al clustering, permettendo così la distribuzione del carico su diversi servers. Il componente singolo del cluster è detto nodo (un’istanza di JBoss) e più nodi possono essere raggruppati insieme definendo la stessa “partition” name nel run.
Per es.
run.sh -c MyApp -b 192.168.0.10 -Djboss.partition.name=myPartition run.sh -c MyApp -b 192.168.0.11 -Djboss.partition.name=myPartition
La maggior parte dei servizi esposti da JBoss AS (JNDI, EJB, RMI, JBoss Remoting, ecc.) richiede che il client ottenga (tramite lookup e download) un oggetto stub (o proxy). Lo stub è generato dal server ed implementa le interfacce di business del servizio. A questo punto il client effettua chiamate “locali” sull’oggetto stub. In un ambiente clusterizzato, lo stub generato dal server è anche un interceptor (proxy) che sa come indirizzare le chiamate ai nodi del cluster (conosce gli indirizzi ip dei nodi disponibili, l’algoritmo per la distribuzione del carico e sa come rimediare ad una chimata fallita). Ogni volta che viene richiesto un servizio viene aggiornato lo stub interceptor alle ultime modifiche nella composizione del cluster.
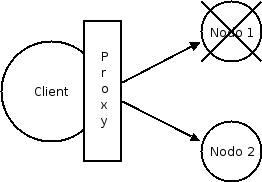
Quando i servizi richiesti viaggiano su HTTP (per es. WebService) al client non è richiesto alcun oggetto stub, il ruolo dell’interceptor viene effettuato da un Load-balancer.
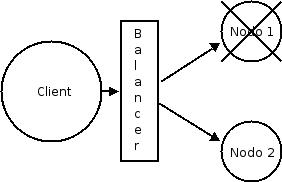
Il servizio di JNDI è vitale per un application server e, in un ambiente clusterizzato di JBoss, è l’HA-JNDI (High Availability JNDI) il servizio che gestisce questo contesto nel cluster. L’albero di contesto JNDI di un cluster è sempre disponibile finchè c’è almeno un nodo nel cluster. A sua volta, ogni nodo del cluster, mantiene un proprio contesto JNDI (locale). Dal lato server, ogni new InitialContext() crea un contesto JNDI locale (per es. le EJB homes). Nel caso di una lookup remota, invece, se l’oggetto richiesto è disponibile nel contesto JNDI clusterizzato allora viene ritornato, altrimenti viene effettuata una lookup nel contesto JNDI locale. Se anche quest’ultima non ritorna l’oggetto richiesto, allora l’HA-JNDI chiede a tutti i nodi del cluster se nella loro JNDI locale è presente l’oggetto richiesto. Se anche questa lookup fallisce viene restituita una NameNotFoundException. Pertanto, un client JNDI deve essere a conoscenza dell’HA-JNDI cluster e come parametro PROVIDER_URL per la lookup dovrà passare la lista degli ip dei nodi del cluster con la porta HA-JNDI (1100).
Per esempio:
Properties p = new Properties(); p.put(Context.INITIAL_CONTEXT_FACTORY, "org.jnp.interfaces.NamingContextFactory"); p.put(Context.URL_PKG_PREFIXES, "jboss.naming:org.jnp.interfaces"); p.put(Context.PROVIDER_URL, "192.168.0.10:1100,192.168.0.11:1100"); return new InitialContext(p);
Tutta questa pappardella mi è servita per arrivare al punto cruciale: a partire dalla versione 3.2.4, JBoss AS supporta l’high availability JMS (HA-JMS) nella configurazione “all”, implementato come servizio singleton clusterizzato in modalità fail-over (se il nodo master diventa irraggiungibile, allora verrà nominato un nuovo master su cui verrà deploiato l’HA-JMS).
Per poter utilizzare l’HA-JMS occorre configurare i servizi JMS in modo identico su ogni nodo del cluster (nella directory $JBOSS_SERVER/deploy-hasingleton/jms). Di default, tutti i servizi JMS vengono persistiti su Hypersonic (hsqldb), un database java che risiede in memoria, il quale è appropriato in fase di sviluppo e di test, ma non è assolutamente adatto in un ambiente di produzione. Infatti in caso di avvio con servizi JMS di default, si riceverebbe un warning sul log di console:
JBoss Messaging Warning: DataSource connection transaction isolation should be READ_COMMITTED, but it is currently NONE. Using an isolation level less strict than READ_COMMITTED may lead to data consistency problems. Using an isolation level more strict than READ_COMMITTED may lead to deadlock.
La prima cosa da fare è quindi settare un db esterno per la persistenza. Dal momento che i servizi JMS utilizzano il datasource di Default (DefaultDS) le strade che si possono percorrere sono 2:
- creo un datasource di default che punta la mio db esterno
- creo un datasource con un mio JNDI name e mi ricordo di modificare anche i files xml dei servizi JMS in modo che utilizzino il mio datasource.
Anche se l’approccio KISS rimane sempre il mio preferito, ho optato per la seconda soluzione, se non altro per avere una visuale più pulita (ammesso che questa possa essere una motivazione valida).
Creo quindi il file del datasource con un mio JNDI Name, che punta ad un database di Oracle10g.
myapp-jms-oracle-ds.xml
<datasources>
<local-tx-datasource>
<jndi-name>MyOracleDS</jndi-name>
<connection-url>jdbc:oracle:thin:@192.168.0.15:1521:XE</connection-url>
<driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
<user-name>myuser</user-name>
<password>myuser</password>
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.OracleExceptionSorter</exception-sorter-class-name>
<metadata>
<type-mapping>Oracle9i</type-mapping>
</metadata>
</local-tx-datasource>
</datasources>
Elimino il file hsqldb-jdbc2-service.xml e creo il file per la configurazione dei servizi di persistenza e cache configurato ad hoc per un db oracle (per altri db, i files di configurazione sono disponibili in $JBOSS_HOME/doc/examples/jms).
myapp-jms-oracle-jdbc2-service.xml (il file può avere qualsiasi nome che rispetti il pattern ..*-service.xml)
<server>
<mbean code="org.jboss.mq.server.jmx.DestinationManager" name="jboss.mq:service=DestinationManager">
<depends optional-attribute-name="MessageCache">jboss.mq:service=MessageCache</depends>
<depends optional-attribute-name="PersistenceManager">jboss.mq:service=PersistenceManager</depends>
<depends optional-attribute-name="StateManager">jboss.mq:service=StateManager</depends>
</mbean>
<mbean code="org.jboss.mq.server.MessageCache" name="jboss.mq:service=MessageCache">
<attribute name="HighMemoryMark">50</attribute>
<attribute name="MaxMemoryMark">60</attribute>
<attribute name="CacheStore">jboss.mq:service=PersistenceManager</attribute>
</mbean>
<mbean code="org.jboss.mq.pm.jdbc2.PersistenceManager" name="jboss.mq:service=PersistenceManager">
<depends optional-attribute-name="ConnectionManager">jboss.jca:service=DataSourceBinding,name=MyOracleDS</depends>
<attribute name="SqlProperties">
INSERT_EMPTY_BLOB = INSERT INTO JMS_MESSAGES (MESSAGEID, DESTINATION, MESSAGEBLOB, TXID, TXOP) VALUES(?,?,EMPTY_BLOB(),?,?)
LOCK_EMPTY_BLOB = SELECT MESSAGEID, MESSAGEBLOB FROM JMS_MESSAGES WHERE MESSAGEID = ? AND DESTINATION = ? FOR UPDATE
BLOB_TYPE=BINARYSTREAM_BLOB
INSERT_TX = INSERT INTO JMS_TRANSACTIONS (TXID) values(?)
INSERT_MESSAGE = INSERT INTO JMS_MESSAGES (MESSAGEID, DESTINATION, MESSAGEBLOB, TXID, TXOP) VALUES(?,?,?,?,?)
SELECT_ALL_UNCOMMITED_TXS = SELECT TXID FROM JMS_TRANSACTIONS
SELECT_MAX_TX = SELECT MAX(TXID) FROM (SELECT MAX(TXID) AS TXID FROM JMS_TRANSACTIONS UNION SELECT MAX(TXID) AS TXID FROM JMS_MESSAGES)
DELETE_ALL_TX = DELETE FROM JMS_TRANSACTIONS
SELECT_MESSAGES_IN_DEST = SELECT MESSAGEID, MESSAGEBLOB FROM JMS_MESSAGES WHERE DESTINATION=?
SELECT_MESSAGE_KEYS_IN_DEST = SELECT MESSAGEID FROM JMS_MESSAGES WHERE DESTINATION=?
SELECT_MESSAGE = SELECT MESSAGEID, MESSAGEBLOB FROM JMS_MESSAGES WHERE MESSAGEID=? AND DESTINATION=?
MARK_MESSAGE = UPDATE JMS_MESSAGES SET TXID=?, TXOP=? WHERE MESSAGEID=? AND DESTINATION=?
UPDATE_MESSAGE = UPDATE JMS_MESSAGES SET MESSAGEBLOB=? WHERE MESSAGEID=? AND DESTINATION=?
UPDATE_MARKED_MESSAGES = UPDATE JMS_MESSAGES SET TXID=?, TXOP=? WHERE TXOP=?
UPDATE_MARKED_MESSAGES_WITH_TX = UPDATE JMS_MESSAGES SET TXID=?, TXOP=? WHERE TXOP=? AND TXID=?
DELETE_MARKED_MESSAGES_WITH_TX = DELETE FROM JMS_MESSAGES MESS WHERE TXOP=:1 AND EXISTS (SELECT TXID FROM JMS_TRANSACTIONS TX WHERE TX.TXID = MESS.TXID)
DELETE_TX = DELETE FROM JMS_TRANSACTIONS WHERE TXID = ?
DELETE_MARKED_MESSAGES = DELETE FROM JMS_MESSAGES WHERE TXID=? AND TXOP=?
DELETE_TEMPORARY_MESSAGES = DELETE FROM JMS_MESSAGES WHERE TXOP='T'
DELETE_MESSAGE = DELETE FROM JMS_MESSAGES WHERE MESSAGEID=? AND DESTINATION=?
CREATE_MESSAGE_TABLE = CREATE TABLE JMS_MESSAGES ( MESSAGEID INTEGER NOT NULL, DESTINATION VARCHAR(255) NOT NULL, TXID INTEGER, TXOP CHAR(1),
MESSAGEBLOB BLOB, PRIMARY KEY (MESSAGEID, DESTINATION) )
CREATE_IDX_MESSAGE_TXOP_TXID = CREATE INDEX JMS_MESSAGES_TXOP_TXID ON JMS_MESSAGES (TXOP, TXID)
CREATE_IDX_MESSAGE_DESTINATION = CREATE INDEX JMS_MESSAGES_DESTINATION ON JMS_MESSAGES (DESTINATION)
CREATE_TX_TABLE = CREATE TABLE JMS_TRANSACTIONS ( TXID INTEGER, PRIMARY KEY (TXID) )
CREATE_TABLES_ON_STARTUP = TRUE
</attribute>
<!-- Uncomment to override the transaction timeout for recovery per queue/subscription, in seconds -->
<!--attribute name="RecoveryTimeout">0</attribute-->
<!-- The number of blobs to load at once during message recovery -->
<attribute name="RecoverMessagesChunk">0</attribute>
</mbean>
</server>
…ciò che è importante da modificare è il parametro di binding al datasource scelto (ammesso che si abbia optato per la seconda soluzione). Sempre nella stessa directory è disponibile anche il file hsqldb-jdbc-state-service.xml, che potrebbe indurre a rimuoverlo, in linea con quanto è stato fatto con hsqldb-jdbc2-service.xml. In realtà hsqldb-jdbc-state-service.xml ha un nome abbastanza infelice, infatti la configurazione è adatta a qualsiasi db SQL92 compliant (per pulizia lo rinominerei in myapp-jms-jdbc-state-service.xml). L’unica cosa da modificare è il puntamento al giusto JNDI name, che è settato a DefaultDS. Occorre infine creare il file per la configurazione della coda/e.
myapp-jms-destination-service.xml:
<server>
<mbean code="org.jboss.mq.server.jmx.Queue" name="jboss.mq.destination:service=Queue,name=MyQueue">
<depends optional-attribute-name="DestinationManager">jboss.mq:service=DestinationManager</depends>
<depends optional-attribute-name="SecurityManager">jboss.mq:service=SecurityManager</depends>
<attribute name="MessageCounterHistoryDayLimit">-1</attribute>
<attribute name="SecurityConf">
<security>
<role name="guest" read="true" write="true"/>
<role name="publisher" read="true" write="true" create="false"/>
<role name="noacc" read="false" write="false" create="false"/>
</security>
</attribute>
</mbean>
</server>
Ho preparato un task ant per effettuare il deploy dei servizi JMS personalizzati:
<target name="install-myapp-jms">
<copy todir="${jboss.server}/deploy-hasingleton/jms" overwrite="yes">
<fileset file="component/jms/etc/myapp-jms-oracle-ds.xml"/>
<fileset file="component/jms/etc/myapp-jms-destinations-service.xml"/>
<fileset file="component/jms/etc/myapp-jms-oracle-jdbc2-service.xml"/>
<fileset file="component/jms/etc/myapp-jms-jdbc-state-service.xml"/>
</copy>
<delete file="${jboss.server}/deploy-hasingleton/jms/hsqldb-jdbc2-service.xml" failonerror="false"/>
</target>
Una volta tirati su i servizi JMS personalizzati, occorre deploiare un solo MDB per tutto il cluster. Creo quindi un MDB semplice che all’arrivo di un messaggio me lo printa sul log.
MyMDB.java:
package test;
import org.apache.log4j.Logger;
import javax.ejb.MessageDrivenBean;
import javax.ejb.EJBException;
import javax.ejb.MessageDrivenContext;
import javax.jms.MessageListener;
import javax.jms.Message;
public class MyMDB implements MessageDrivenBean, MessageListener {
private static final Logger logWriter = Logger.getLogger(MyMDB.class);
/**
* Message driven context
*/
private MessageDrivenContext messageDrivenContext;
public InboundRisultatiBean() {}
public void onMessage(Message message) {
logWriter.debug("---- Called onMessage() ----");
logWriter.debug("Messaggio: " + message);
logWriter.debug("---- Exit onMessage() ----");
}
public void ejbRemove() throws EJBException {}
public void setMessageDrivenContext(MessageDrivenContext messageDrivenContext) throws EJBException {
this.messageDrivenContext = messageDrivenContext;
}
public void ejbCreate() {}
}
Setto la transazione a Required solo per il metodo onMessage().
ejb-jar.xml:
<ejb-jar>
<enterprise-beans>
<message-driven>
<description>Singleton MDB, MyMDB</description>
<ejb-name>MyMDB</ejb-name>
<ejb-class>test.MyMDB</ejb-class>
<transaction-type>Container</transaction-type>
<acknowledge-mode>Auto-acknowledge</acknowledge-mode>
<message-driven-destination>
<destination-type>javax.jms.Queue</destination-type>
</message-driven-destination>
</message-driven>
</enterprise-beans>
<assembly-descriptor>
<container-transaction>
<method>
<ejb-name>MyMDB</ejb-name>
<method-name>onMessage</method-name>
</method>
<trans-attribute>Required</trans-attribute>
</container-transaction>
</assembly-descriptor>
</ejb-jar>
Infine setto in jboss.xml il bind dell’MDB alla mia coda e soprattutto scelgo come configuration-name “Singleton Message Driven Bean”, una configurazione già disponibile in JBoss AS senza dover specificare altri parametri nel tag <container-configurations>:
<jboss>
<enterprise-beans>
<message-driven>
<ejb-name>MyMDB</ejb-name>
<configuration-name>Singleton Message Driven Bean</configuration-name>
<destination-jndi-name>queue/GTSRisultatiQueue</destination-jndi-name>
</message-driven>
</enterprise-beans>
</jboss>
Impacchetto il tutto in un jar e deploio su tutti i nodi nella directory $JBOSS_SERVER/deploy.hasingleton. Se il deploy è effettuato a caldo (hot-deploy), quando tutti i servizi JMS sono stati startati non si dovrebbero ricevere errori, se invece si avvia JBoss con l’mdb già presente in directory si dovrebbe ricevere un errore di JNDI name non trovata (si tratta di una JNDI name dei servizi JMS, per es. CachedConnectionManager, DefaultJMSProvider…).Tutto ciò avviene, in quanto, JBoss tenta di deploiare il jar (e quindi di attaccare l’mdb alla coda) quando ancora i servizi JMS non sono stati avviati.
Una delle soluzioni trovate in rete (che come al solito a me non ha funzionato), è quella di settare a true il parametro RecursiveSearch nel file $JBOSS_SERVER/conf/jboss-service.xml. Con riferimento invece alle dipendenze dei vari servizi di JBoss, ho modificato il file ejb-deployer.xml in $JBOSS_SERVER/deploy aggiungendo la dipendenza a ServerSessionPoolMBean (ultimo servizio JMS ad essere avviato):
<depends>jboss.mq:service=ServerSessionPoolMBean,name=StdJMSPool</depends>
Grazie a quest’ultimo ritocco tutti i tasselli dovrebbero essersi incastrati perfettamente… per verificarlo basta la prova del nove. Ho messo in cluster 3 nodi jboss, deploiando singolarmente il mio mdb. L’mdb è stato creato solo sul nodo su cui ho effettuato per primo il deploy. Ho provato ad inviare con uno stress test una serie di messaggi sulla coda con un client esterno a cui ho fornito la lista di provider url HA-JNDI. Tutti i msg sono stati letti in sequenza (senza concorrenza, essendoci un solo mdb) dall’unico nodo su cui era stato deploiato l’mdb. Infine con mia grande soddisfazione, ho buttato giù il nodo master dell’mdb e automaticamente il cluster ha scelto un nuovo nodo su cui creare l’mdb.
Ripristinare GRUB
Stasera sono tornato a casa, ho acceso il portatile (tanto per cambiare), e con mio grande stupore, ubuntu non si è avviato…
L’errore che ricevevo è il seguente:
/bin/sh : can't access tty; job control turned off
Ho cercato di ricordare se, prima di spegnerlo, avessi installato qualche nuovo aggiornamento o cambiato qualche configurazione. Probabilmente qualche aggiornamento devo averlo installato… ma non ricordavo certo cosa …così, armato di Google, mi sono messo alla ricerca della soluzione.
Quasi tutte le ricerche mi portavano a Grub. Diciamo che, inizialmente, ero abbastanza scettico perchè Grub si avviava senza problemi e lo stesso Windows (che ho sull’altra partizione) non mostrava cedimenti. Comunque, sebbene scettico, ho provato a ripristinare Grub (cosa che non avevo mai fatto… fino a questa sera).
Ho scaricato al volo la versione Desktop di UBUNTU 6.06.01, l’ho masterizzata e avviata in modalità live. Ho aperto un terminale e ho montato la partizione su cui è installato ubuntu in una directory temporanea e ho reso quest’ultima una directory radice:
sudo mkdir /mnt/ubuntu sudo mount -t ext3 /dev/hda2 /mnt/ubuntu sudo chroot /mnt/ubuntu
A questo punto ho reinstallato grub:
sudo grub-install /dev/hda
Con poca fiducia (sulla bontà della cosa) ho riavviato e questa volta ubuntu si è avviato senza problemi… Ho perso anche un quarto d’ora nel cercare di capire che cosa avesse sfasciato grub, ma non ho trovato nulla. L’importante è aver risolto…
Transazioni Hibernate con JTA
Fino ad oggi ho sempre gestito le transazioni con Hibernate tramite il bind della sessione al corrente thread java. Questa soluzione, in un’ambiente di EJB multi-tier, risulta inefficiente nel momento in cui la transazione richiede 2 o più chiamate all’ejb che funge da DAO.
Come si evince dalla figura, dopo la chiamata (1), l’ejb di DaoManager mi restituisce un oggetto hibernate idradato ma, gestendo lui le sessioni, questa risulta ormai chiusa e anche operazioni di logica banali che io faccio su questo oggetto potrebbero scatenarmi un’eccezione (si pensi ad un’oggetto con una lista lazy non inizializzata, anche un semplice set su un campo non lazy può scatenare una LazyInitizalizationException).
La soluzione a questo problema potrebbe essere quella di aprire la sessione hibernate a livello dell’ejb di Business Logic. Effettivamente funziona, ma passare la sessione ad ogni chiamata all’ejb di DaoManager è poco pratico e soprattutto mi vincolerebbe a farlo anche nel caso in cui una semplice transazione si traduce in una chiamata 1:1 tra ejb di logica e DAO.
Per chi utilizza una versione di Hibernate precedente alla 3.0.1, questa rimane la soluzione migliore, indipendentemente dall’application server su cui gira. Dalla versione 3.0.1, Hibernate, è invece in grado di lavorare in un ambiente che supporta JTA, gestendo automaticamente il bind della sessione hibernate alla corrente transazione JTA. Lavorando con JBoss 4.0.4.GA ho provato e testato con successo questa implementazione.
Ho modificato la HibernateUtil class nel mio framework, riducendola al nocciolo della semplice lookup della SessionFactory:
static {
try {
Context ctx = new InitialContext();
sessionFactory = (SessionFactory)ctx.lookup("java:/hibernate/MySessionFactory");
} catch (Throwable ex) {
logWriter.error("Inizializzazione SessionFactory fallita." + ex);
initializationException =
new FrameworkException("Inizializzazione SessionFactory fallita.", ex);
}
}
public static SessionFactory getSessionFactory() throws FrameworkException {
if (initializationException != null){
throw initializationException;
}
return sessionFactory;
}
Ho modificato il file di configurazione hibernate-service.xml per il servizio har:
<server>
<mbean code="org.hibernate.jmx.HibernateService" name="jboss.har:service=Hibernate-GTS">
<attribute name="Datasource">java:/MyDatasource</attribute>
<attribute name="Dialect">org.hibernate.dialect.Oracle9Dialect</attribute>
<attribute name="JndiName">java:/hibernate/MySessionFactory</attribute>
<attribute name="CacheProviderClass">
org.hibernate.cache.HashtableCacheProvider</attribute>
<attribute name="ShowSqlEnabled">false</attribute>
<attribute name="TransactionStrategy">
org.hibernate.transaction.JTATransactionFactory</attribute>
<attribute name="TransactionManagerLookupStrategy">
org.hibernate.transaction.JBossTransactionManagerLookup</attribute>
<attribute name="MapResources">
example/MyPOJO1.hbm.xml,
example/MyPOJO2.hbm.xml
</attribute>
</mbean>
</server>
…e infine ho piazzato nel DaoManager un metodo privato di utilità per il reperimento della sessione di Hibernate, che utilizzerò in ogni metodo:
private Session getCurrentSession() throws DaoManagerException {
try {
return HibernateUtil.getSessionFactory().getCurrentSession();
} catch (FrameworkException ex) {
logWriter.error("---- Errore nel recuperare la SessionFactory", ex);
throw new DaoManagerException("Errore nel recuperare la SessionFactory", ex);
} catch (HibernateException ex){
logWriter.error("---- Errore nel recuperare la Sessione hibernate", ex);
throw new DaoManagerException("Errore nel recuperare la Sessione hibernate", ex);
}
}
In questo modo nell’ejb di BusinessLogic posso implementare tutta la logica che voglio tra le varie chiamate al DaoManager senza preoccuparmi della sessione di Hibernate:
try {
MyPOJO1 p1 = localDaoManager.getPOJO1ById(id);
// do something
localDaoManager.doSomething(....);
} catch (DaoManagerException ex){
sessionContext.setRollbackOnly();
}
Il vantaggio di tutto questo è che la sessione di Hibernate è legata alla transazione JTA (come trasaction attribute ho impostato RequiresNew per l’ejb di BusinessLogic e Mandatory per l’ejb di DAOManager). La sessione viene automaticamente aperta quando getCurrentSession() è invocato per la prima volta e viene automaticamente chiusa quando la termina la transazione.
